
HashMap
在开发中,我们经常会使用HashsMap来管理组织我们的数据,但是HashMap却会消耗掉许多内存,即便是我们的数据并不大。为了大家能理解我下面的内容,建议读者google一下HashMap的原理或阅读源码,来了解hash碰撞与HashMap的大小分配。
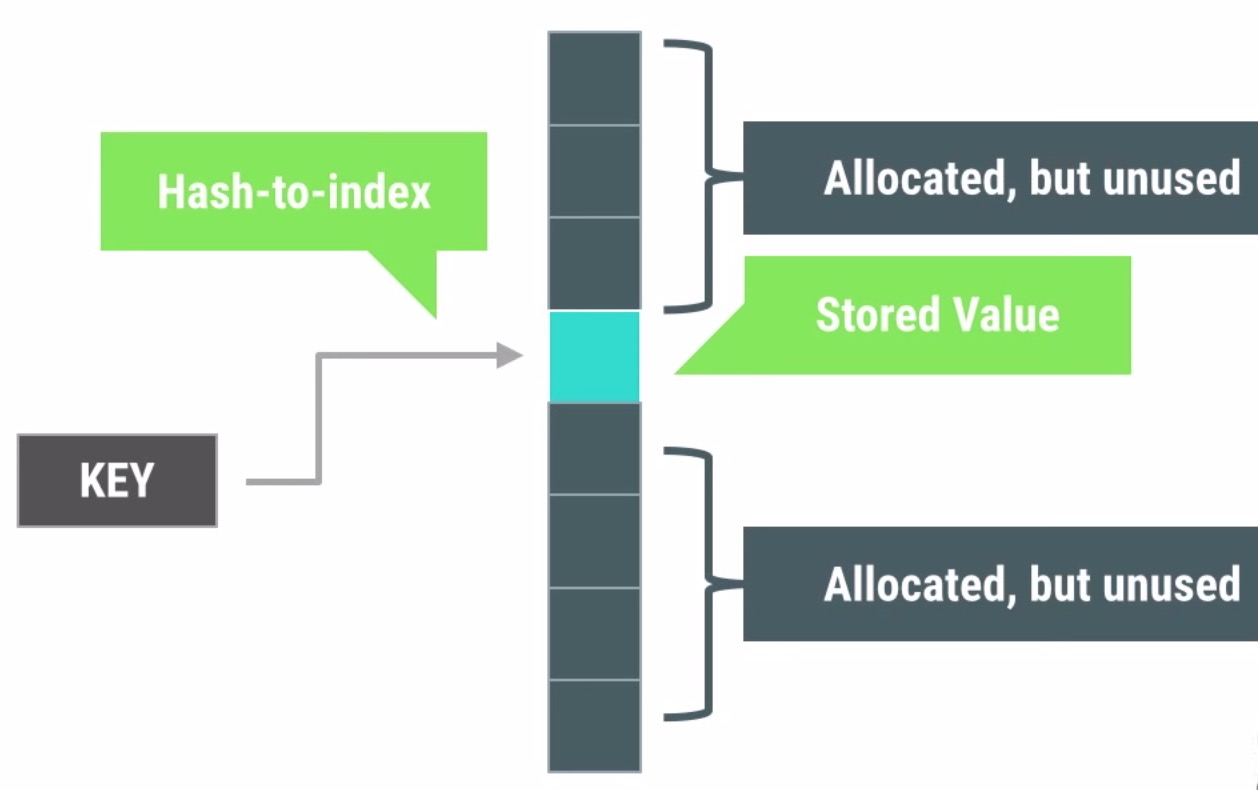
HashMap初始化就分配了内存空间,若分配的空间太小就会而数据太多久会发生hash碰撞。比如有20000个键值对要放到初始大小为16的HashMap中,就会发生多次hash碰撞并resize大小。想要减少hash碰撞的发生,只有加大HashMap的大小才行。值在HashMap的table中存储位置是由hash运算得出的,会出现上图中的,分配了空间却没有被使用。造成了空间的浪费。
ArrayMap
Android中有一个新的类型ArrayMap来解决HashMap带来的内存浪费问题。
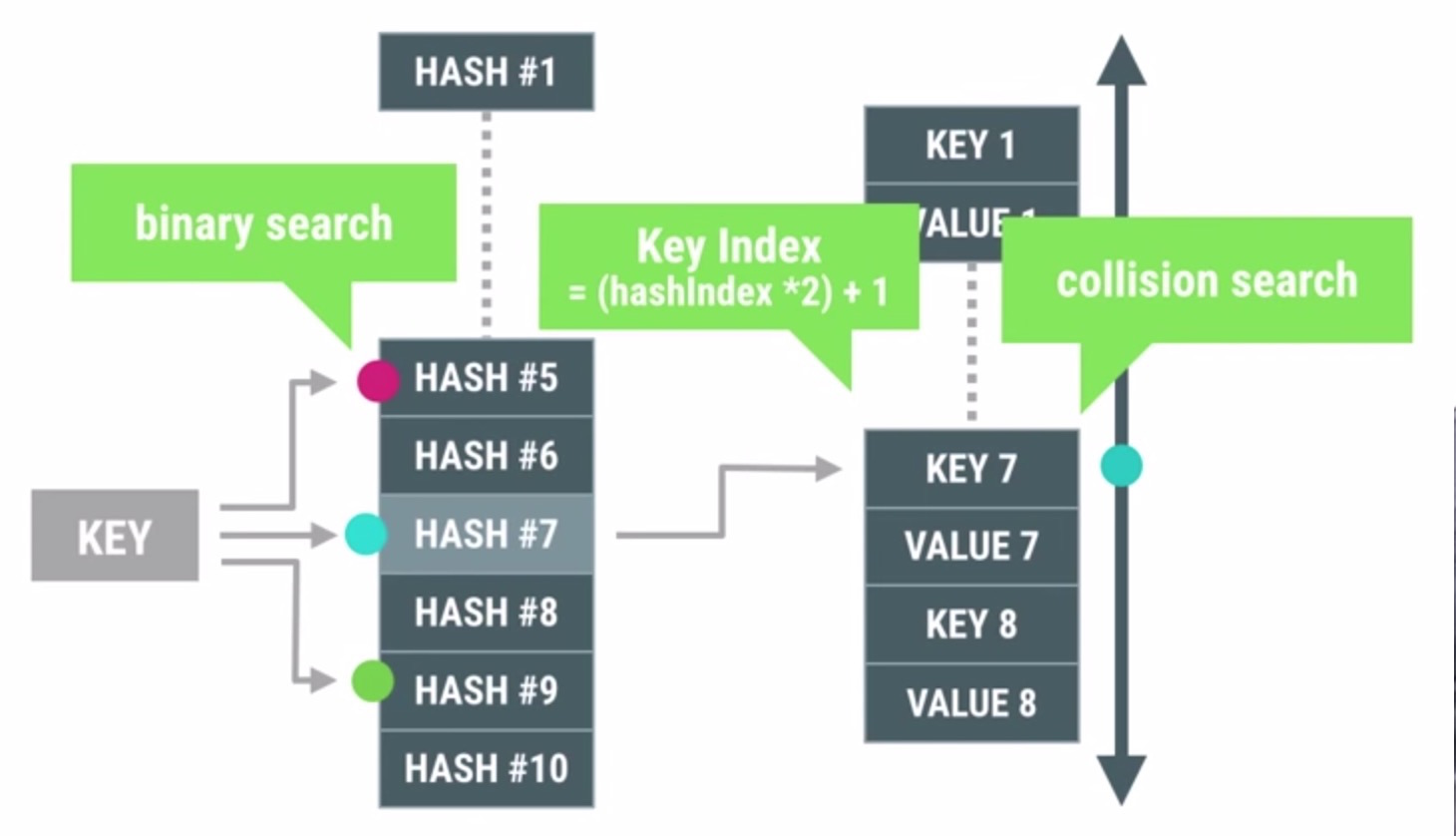
上图为ArrayMap的查找原理图。可见ArrayMap主要使用到了两个数组:一个hash数组,一个键值对数组。Key的hash值保存在hash列表中。先用二分查找法查找Key的hash值在hash数组中的index,再通过计算(index*2)+1得到key在键值对数组中的位置,对应的值的位置再加1即可得到。
相比HashMap在出现hash碰撞时使用链表遍历的方式来查找确实会有性能上的提升。
然而ArrayMap的插入和删除则显得非常暴力了。我在这里可以比喻为腰斩。下面是增加和删除的源码:
/**
* Add a new value to the array map.
* @param key The key under which to store the value. If
* this key already exists in the array, its value will be replaced.
* @param value The value to store for the given key.
* @return Returns the old value that was stored for the given key, or null if there
* was no such key.
*/
@Override
public V put(K key, V value) {
final int hash;
int index;
if (key == null) {
hash = 0;
index = indexOfNull();
} else {
hash = key.hashCode();
index = indexOf(key, hash);
}
if (index >= 0) {
index = (index<<1) + 1;
final V old = (V)mArray[index];
mArray[index] = value;
return old;
}
index = ~index;
if (mSize >= mHashes.length) {
final int n = mSize >= (BASE_SIZE*2) ? (mSize+(mSize>>1))
: (mSize >= BASE_SIZE ? (BASE_SIZE*2) : BASE_SIZE);
if (DEBUG) Log.d(TAG, "put: grow from " + mHashes.length + " to " + n);
final int[] ohashes = mHashes;
final Object[] oarray = mArray;
allocArrays(n);
if (mHashes.length > 0) {
if (DEBUG) Log.d(TAG, "put: copy 0-" + mSize + " to 0");
System.arraycopy(ohashes, 0, mHashes, 0, ohashes.length);
System.arraycopy(oarray, 0, mArray, 0, oarray.length);
}
freeArrays(ohashes, oarray, mSize);
}
if (index < mSize) {
if (DEBUG) Log.d(TAG, "put: move " + index + "-" + (mSize-index)
+ " to " + (index+1));
System.arraycopy(mHashes, index, mHashes, index + 1, mSize - index);
System.arraycopy(mArray, index << 1, mArray, (index + 1) << 1, (mSize - index) << 1);
}
mHashes[index] = hash;
mArray[index<<1] = key;
mArray[(index<<1)+1] = value;
mSize++;
return null;
}
/**
* Remove an existing key from the array map.
* @param key The key of the mapping to remove.
* @return Returns the value that was stored under the key, or null if there
* was no such key.
*/
@Override
public V remove(Object key) {
final int index = indexOfKey(key);
if (index >= 0) {
return removeAt(index);
}
return null;
}
/**
* Remove the key/value mapping at the given index.
* @param index The desired index, must be between 0 and {@link #size()}-1.
* @return Returns the value that was stored at this index.
*/
public V removeAt(int index) {
final Object old = mArray[(index << 1) + 1];
if (mSize <= 1) {
// Now empty.
if (DEBUG) Log.d(TAG, "remove: shrink from " + mHashes.length + " to 0");
freeArrays(mHashes, mArray, mSize);
mHashes = EmptyArray.INT;
mArray = EmptyArray.OBJECT;
mSize = 0;
} else {
if (mHashes.length > (BASE_SIZE*2) && mSize < mHashes.length/3) {
// Shrunk enough to reduce size of arrays. We don't allow it to
// shrink smaller than (BASE_SIZE*2) to avoid flapping between
// that and BASE_SIZE.
final int n = mSize > (BASE_SIZE*2) ? (mSize + (mSize>>1)) : (BASE_SIZE*2);
if (DEBUG) Log.d(TAG, "remove: shrink from " + mHashes.length + " to " + n);
final int[] ohashes = mHashes;
final Object[] oarray = mArray;
allocArrays(n);
mSize--;
if (index > 0) {
if (DEBUG) Log.d(TAG, "remove: copy from 0-" + index + " to 0");
System.arraycopy(ohashes, 0, mHashes, 0, index);
System.arraycopy(oarray, 0, mArray, 0, index << 1);
}
if (index < mSize) {
if (DEBUG) Log.d(TAG, "remove: copy from " + (index+1) + "-" + mSize
+ " to " + index);
System.arraycopy(ohashes, index + 1, mHashes, index, mSize - index);
System.arraycopy(oarray, (index + 1) << 1, mArray, index << 1,
(mSize - index) << 1);
}
} else {
mSize--;
if (index < mSize) {
if (DEBUG) Log.d(TAG, "remove: move " + (index+1) + "-" + mSize
+ " to " + index);
System.arraycopy(mHashes, index + 1, mHashes, index, mSize - index);
System.arraycopy(mArray, (index + 1) << 1, mArray, index << 1,
(mSize - index) << 1);
}
mArray[mSize << 1] = null;
mArray[(mSize << 1) + 1] = null;
}
}
return (V)old;
}在代码中,可以看到当内部数组空间不足时,每次增加10%的空间,相比HashMap每次加倍,更加节省空间。两者都是重新分配数组空间并将原数组拷贝到新数组的方式来增加空间。
增加元素时当计算的key的index大于0小于mSize时,会将数组中下标大于index的数组全部向后拷贝,然后将新的值赋值到index所在位置。相比HashMap使用单向链表,直接在链表尾部添加值更耗时。
移除元素则差不多一样,将原数组临时存放,然后将index前后的数组覆盖原数组即可。
可见在内存优化上,ArrayMap还是用性能为代价的。但是当元素只有几百的时候这些性能代价就微不足道了。
ArrayMap还有另外的优点,HashMap在初始化时就占用了默认大小内存空间。然而ArrayMap则不会占用。
ArrayMap比HashMap更容易遍历,相比HashMap的迭代方式更加节省内存空间。
//ArrayMap
for(int i = 0;i< map.size();I++){
Object keyObj = map.ketAt(i);
Object valObj = map.valueAt(i);
…
}
//HashMap
for(Iterator it = map.iterator();it.hasNest();){
Object obj = it.next();
…
}何时使用ArrayMap
既然ArrayMap相比HashMap既有优点又有不足。再什么情况下我们应该使用ArrapMap呢?
- 元素个数小于1000。
- Map嵌套Map。
在这样的情况下,我们有足够的理由使用ArrayMap来节省内存,而不用理会那微不足道的性能消耗。
